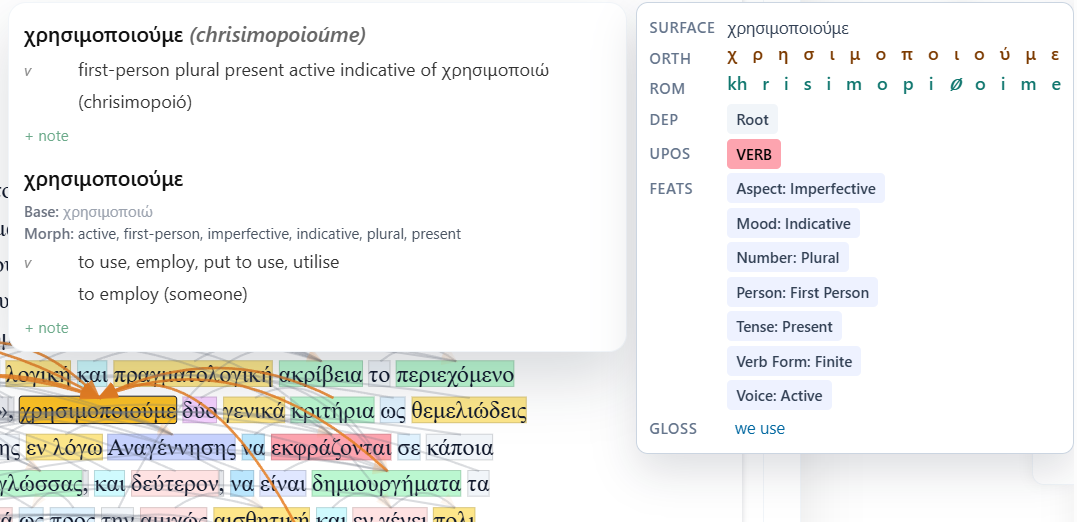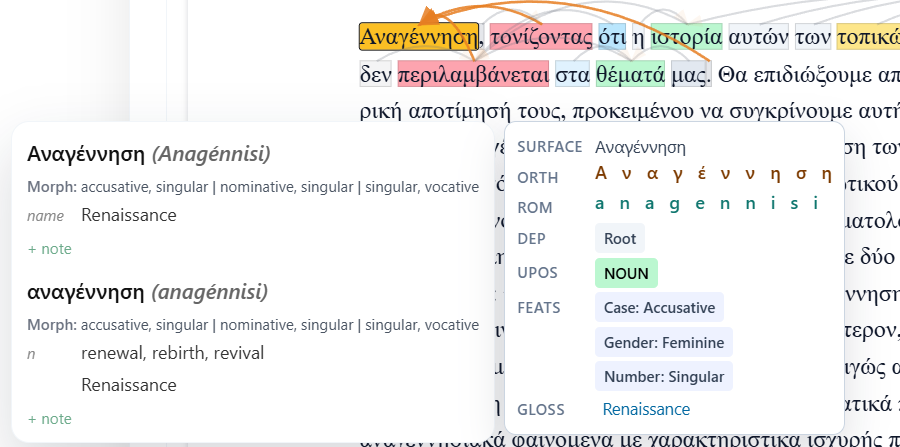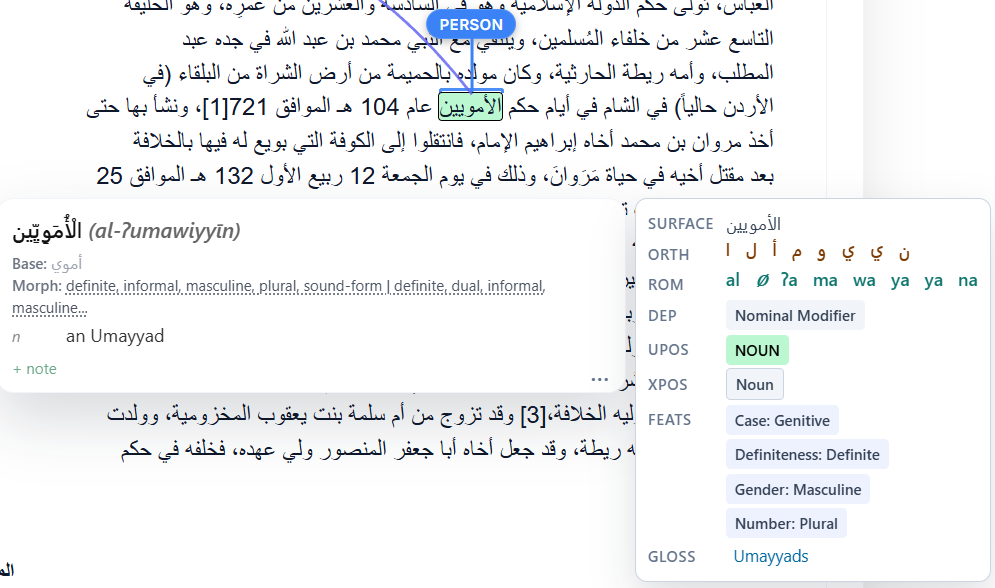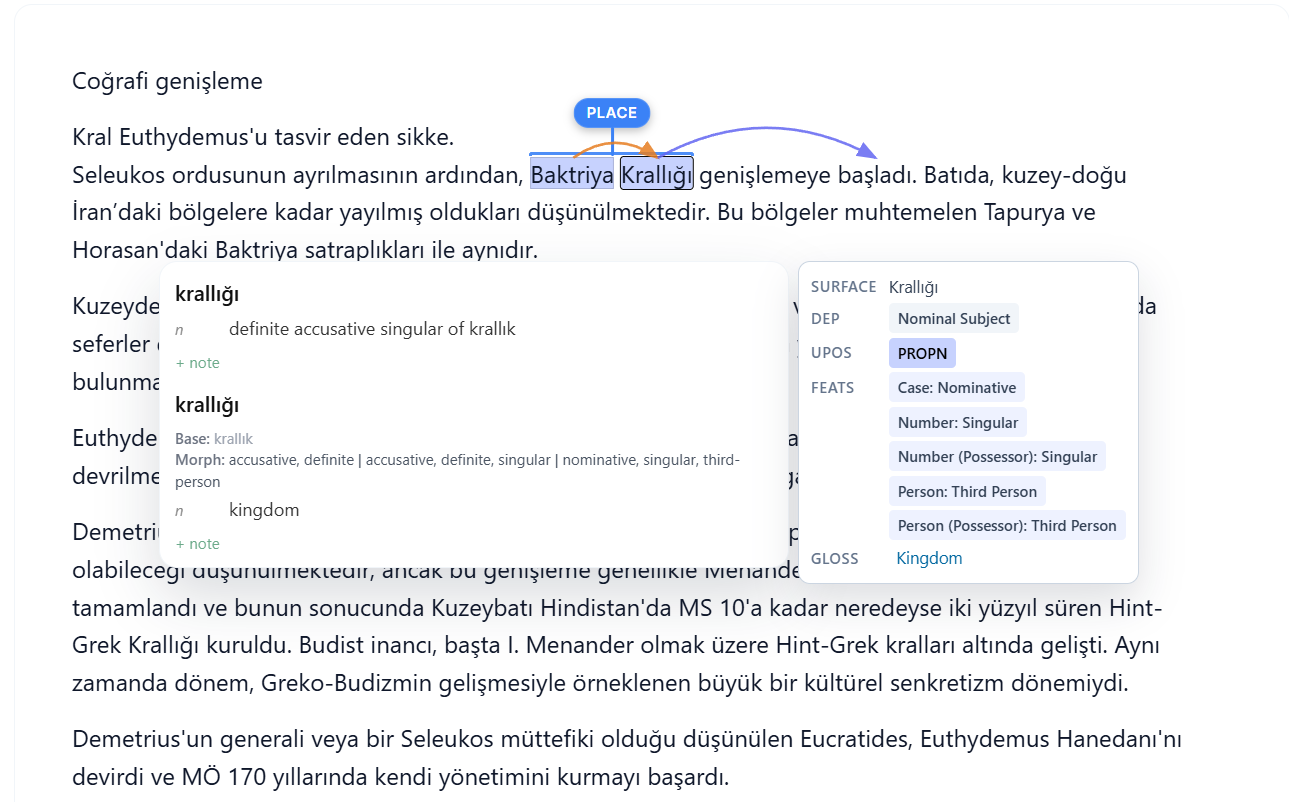

Read PDFs, ebooks, and Word docs with their layout intact
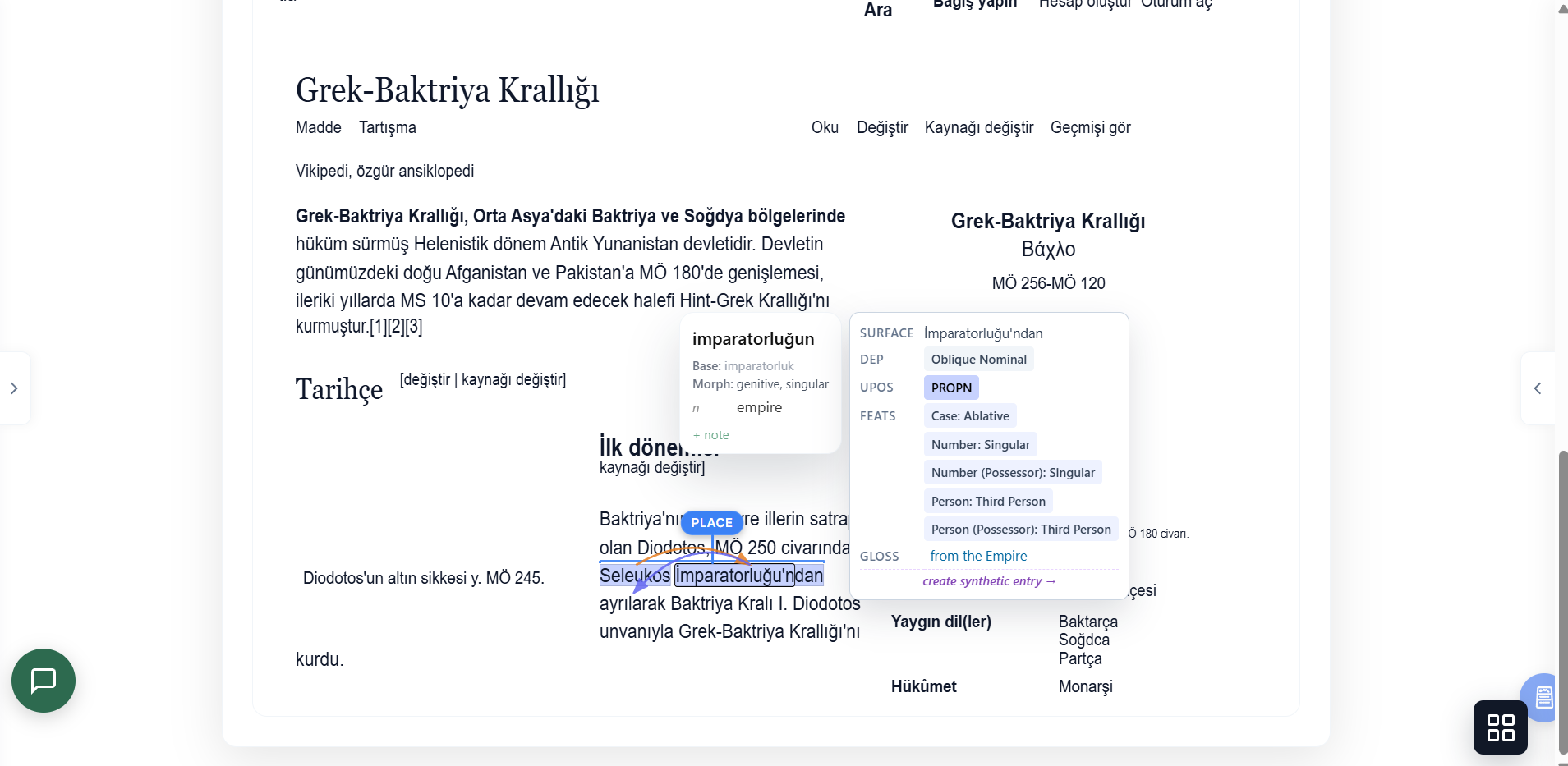
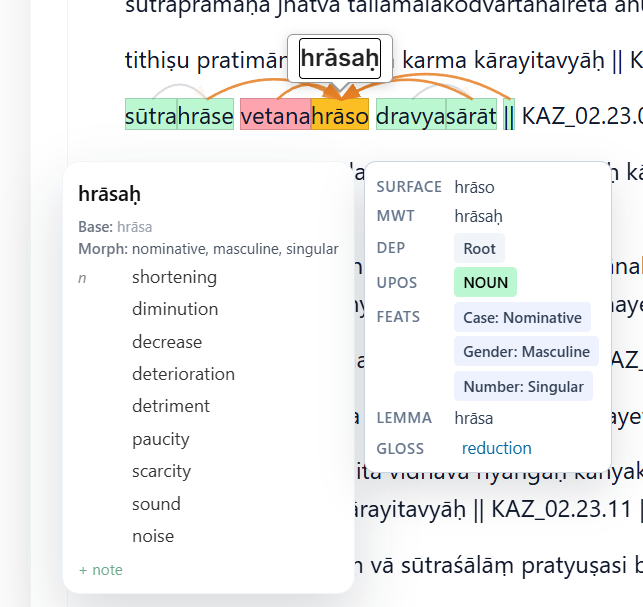
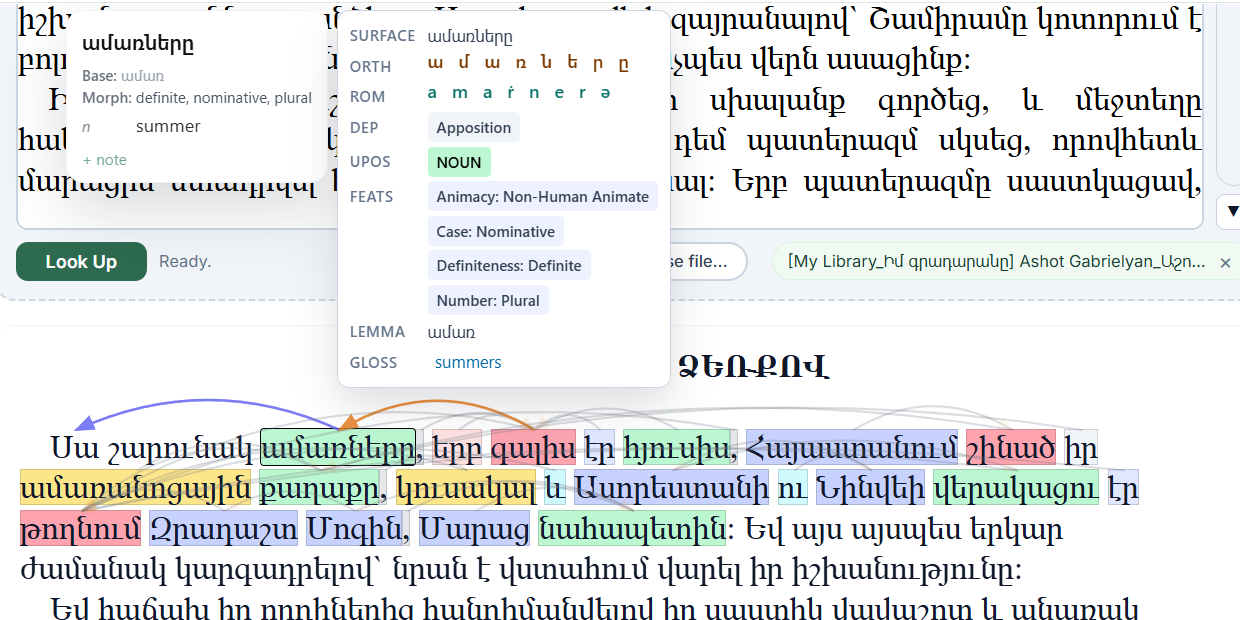
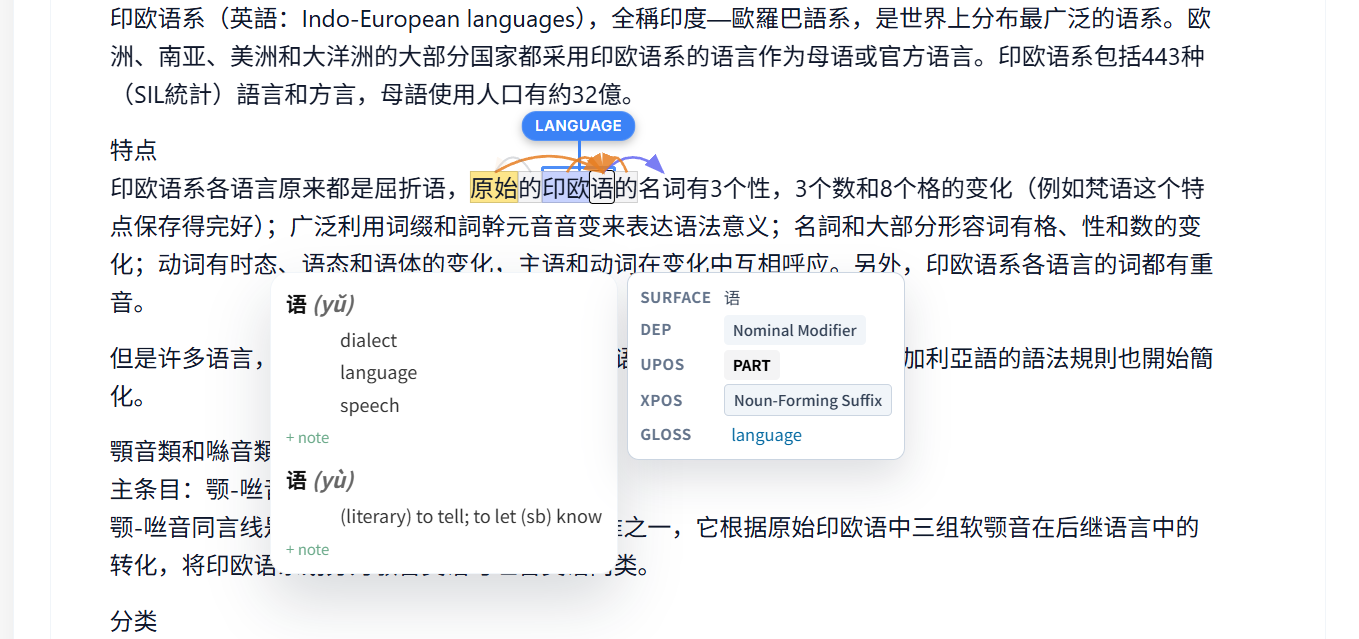
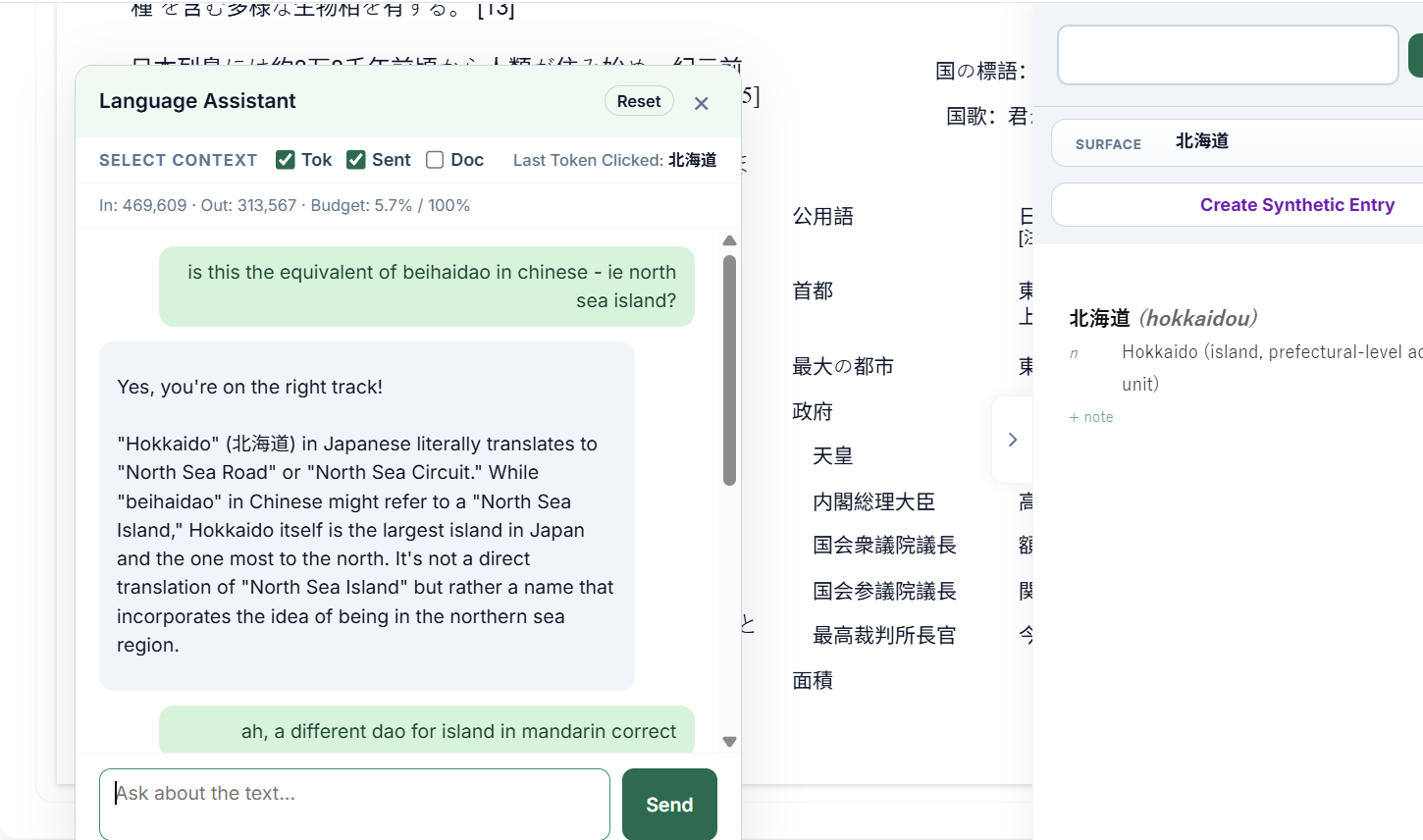
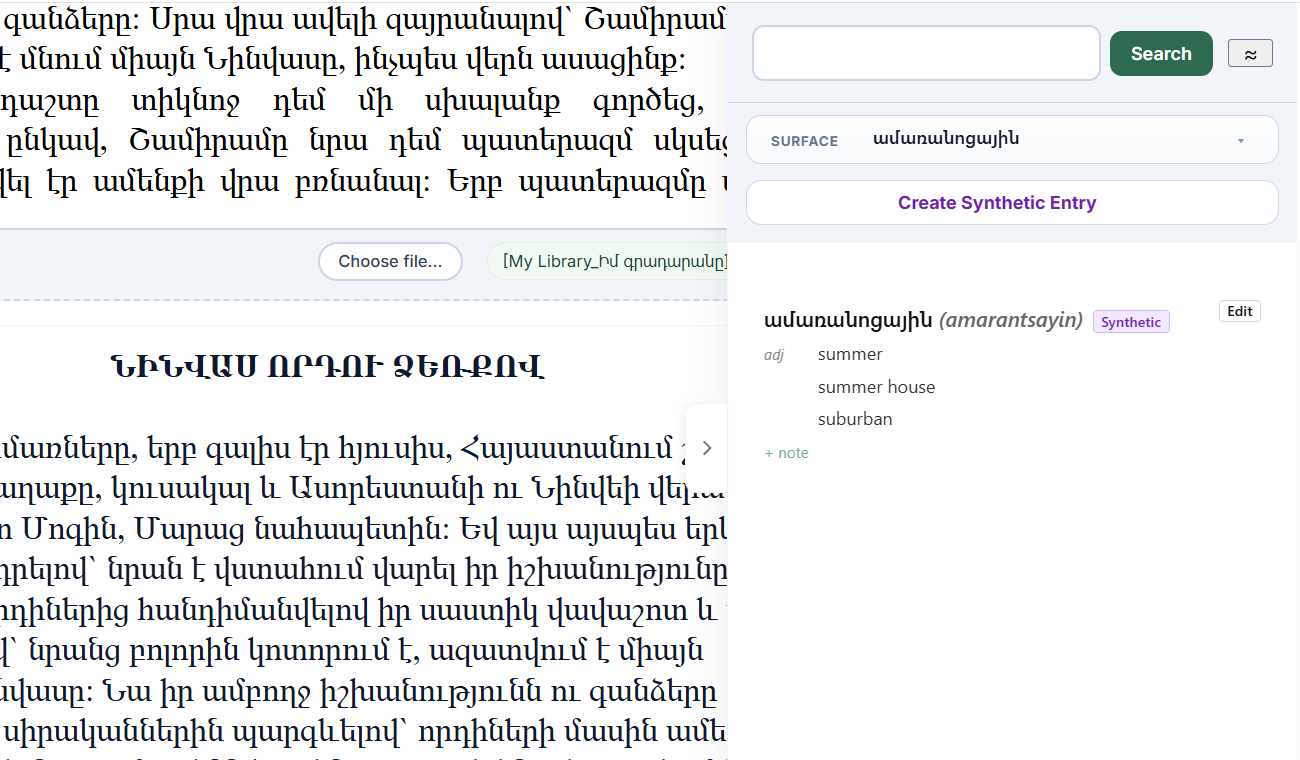
Documents are ingested with their original page geometry preserved — page numbers, running headers, centred text blocks, line wrapping, and book typography. Dependency arcs are drawn directly over the live text, so syntax is visible on the page.